An Intelligent Compute Cluster Autoscaler
|
Luna provisions just-in-time, right-sized, and cost-effective compute for your apps. This includes the full lifecycle of your app, from when it starts to when it terminates. The Compute is scaled both up and down as your workloads and demand change.
Luna reduces operational complexity and prevents wasted spend. Ideally suited for dynamic and bursty workloads. Deploy your ML platforms like Ray, dev/test workloads, as well as workloads that need special resources such as GPU and ARM on EKS, GKE, AKS, and OKE with confidence using Luna! |

|
Luna in Action
Why Luna?
|
Save Money |
Save GPU |
Multi-Cloud |
What Kind of Workloads Does Luna Accommodate?
|
|
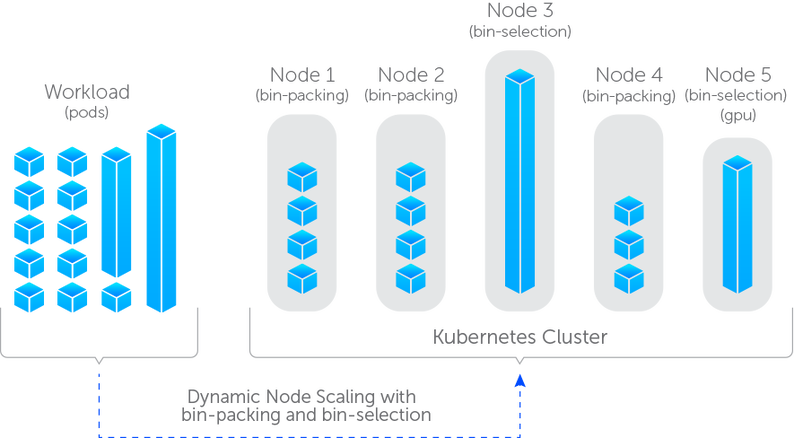
How it Works
Feature Comparison
